
Summary
We propose a new vector representation that combines lexical comparisons with distributed vectors to enhance the most salient features used to determine lexical similarity. In terms of performance, these adjusted vector representations largely surpass the standard vector model, achieving cross-word categories (adjectives, names, verbs) that distinguish between two antonymous and synonym semantic relationships with an average precision of 0.66- 0.76. In addition, we integrate lexical contrast vectors into the objective function based on the skip-gram model. The new vector representation is superior to the state-of-the-art model in the use of Simlex-999 in predicting lexical similarity and distinguishing anti-synonymous terms.
1 Introduction
Antonyms and synonyms, as two kinds of lexical semantic relations, are an important part of mental lexicon (Miller & Fellbaum, 1991). For the two words with opposite meanings, we call them antonyms. For two words with the same meaning, we call them synonyms (Deese, 1965; Lyons, 1977). From a computational point of view, distinguishing between antonyms and synonyms has a very important role for NLP applications, such as machine translation and text implication. These applications are beyond the ordinary meaning of semantic association and require the recognition of specific semantic relationships. However, because some words can be replaced with each other, antonyms and synonyms often appear in similar contexts, thus increasing the difficulty of distinguishing the two types of words.
Distributed semantic models (DSMs) provide a representation of word-meaning vectors that determine the semantic relationships between words (Budanitsky & Hirst, 2006; Turney & Pantel, 2010). The distributed semantic model is based on the "Distribution Hypothesis" (Harris, 1954; Firth, 1957). This hypothesis advocates the existence of a semantic relationship between words with similar distribution characteristics. For ease of calculation, each word is represented by a vector of weighted features, which are generally closely related to words that appear in a particular context. However, DSMs can search synonyms for synonyms (for example, formal and conventional) and antonyms (for example, formal and informative), but cannot fully distinguish these two semantic relations.
In recent years, a large number of distribution methods have been used to distinguish between antonyms and synonyms. Usually, these distribution methods are combined with lexical resources such as dictionaries or taxonomies. For example, Lin et al. (2003) use dependent triples to extract vocabularies with similar distribution characteristics, and in the subsequent process, those vocabularies often appearing in a “from x to Y†or “x or y†distribution. Mohammad et al. (2013) believe that the pairs of words appearing in the same lexical dictionary have a close relationship in meaning and are labeled as synonyms. On the contrary, those pairs of words that often appear in the opposite dictionary classification or paragraph are Marked as an antonym. Scheible et al. (2013) believe that, based on appropriate semantic features and using a simple lexical space model, the distributional characteristics of two semantic relationships between antonyms and synonyms can be distinguished. The purpose of Santus et al. (2014a, 2014b) is to use vector representation to identify the most significant dimension of significance, and to report a new distributed measurement method based on average accuracy and an entropy-based measurement method to distinguish antonyms from Synonyms are two kinds of semantic relations (further distinguishing between aggregated semantic relations).
Recently, the distinction between antonyms and synonyms has also become the focus of the vocabulary vector model. For example, Adel and Schutze (2014) integrated a core reference chain extracted from a large corpus into a skip-gram model that aims to generate vocabulary vectors and distinguish synonyms. Ono et al. (2015) proposed a dictionary-based vocabulary vector representation to identify antonyms. Two models were used during the study: the WE-T model for training vocabulary vectors based on dictionary information and the WE-TD model for integrating distribution information into the WE-T model. Pham et al. (2015) introduced a multitasking vocabulary comparison model that incorporates “WordNet†into a skip-gram model to optimize semantic vectors to predict contextual information. This model provides negative examples in two common semantic tasks and distinguishes between antonyms and synonyms. It is superior to the standard skip-gram model in performance.
In this paper, we propose two methods for using lexical contrast information and vocabulary vectors in distributed semantic spaces to distinguish antonyms from synonyms. First, assuming that the semantic overlap between synonyms is more overlapped with that between antonyms, we combine lexical contrast information with distributed vectors to enhance the most prominent lexical features that can determine lexical similarity. Secondly, we use the negative examples to extend the model for the skip-gram model (Mikolov et al., 2013b) and obtain a new model to integrate the lexical contrast information into the objective function. There is a new model that we propose to predict lexical similarity by optimizing semantic vectors, and to distinguish between antonyms and synonyms. In the task of distinguishing between antonym-synonyms and lexical similarity, the improved lexical vector representation is superior to the state-of-art model.
2. Our method
In this section, we will enumerate the two contributions of this article: a new vector representation that can improve the weight features to distinguish between antonyms and synonyms (see 2.1), an integration of the improved vector representation Objective function to predict lexical similarity and identify the skip-gram extension model of antonyms (see 2.2).
2.1 Improve the Weight of Feature Vectors
When distinguishing similarities between vocabularies, we aim to improve the feature vectors by enhancing the most salient vector features and not overemphasizing those less important vector features. We start with the co-occurrence frequency of vocabulary in the standard corpus and use locally shared information to determine the original length of lexical features. Our score 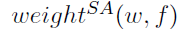 Then define the target word w and feature f:
Then define the target word w and feature f:
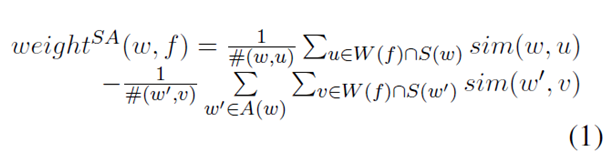
The new weightSA score calculation method for target word w and feature f uses the difference between the average similarity between the synonym and the target word, and the average similarity between the antonym and the target word. Only those vocabularies included in the calculation process have a positive initial LMI score corresponding to feature f. We use the cosine of the distance to calculate the similarity between two vocabulary vectors. If the vocabulary w is not associated with any synonym or antonym in the vocabulary resources we use, or if there is no co-occurrence relationship between a semantic feature and the vocabulary w, we define the result as zero.
The basis of the vocabulary comparison information in our new weightSA calculation process is as follows. The most prominent semantic features of a vocabulary may also represent the most obvious semantic features of its synonyms, but it represents the most inconspicuous semantic features of its antonyms. For example, a feature conception only co-occurs with a synonym for the adjective formal, and a synonym with its antonym informal or informal does not occur at the same time. The average similarity between Formal and its synonyms minus the average similarity between informal and its synonyms, the weightSA (formal, conception) obtained should be a high positive value. On the contrary, features, such as issues, can co-occur with many different adjectives, and the weightSA (formal, issue) corresponding to their eigenvalues ​​should approach zero because the average similarity between formal and its synonyms is extremely large. Finally, features such as rumor only co-occur with informal and its synonym, and do not co-occur with the original target adjective formal and its synonym. The corresponding weightSA (formal, rumor) of this feature should be low. Table 1 provides schema results for calculating the new weightSA of the target formal.
Since the number of antonyms is generally less than the number of synonyms, we will further expand the number of antonyms: We treat all synonyms of an antonym as antonyms of that word. For example, compared to its 31 synonyms, the target word good has only two antonyms (bad and evil) in WordNet. Therefore, we also use the synonym for bad and evil as an antonym of good.

Figure 1: Illustration of the score calculation for the target adjective formal.
2.2 Integrate distributed lexical comparison into skip-gram model
The model we propose is based on the model of Levy and Goldberg (2014). The model indicates that the objective function of the negative sample skip-gram model should be defined as follows:

The first expression in Equation 2 represents the co-occurrence of target word w with context c in a contextual window. The number of occurrences of the target word and the appearance of the context are defined as (w,c). The second expression represents a negative example, where k represents the number of negative sample terms and (w) represents the number of occurrences of the target word w.
In order to embed the lexical contrast information in the SGN model, we propose an objective function in Equation 3, refer to the contextual information of the target word to improve the contrast of the lexical feature distribution. In Equation 3, V represents a vocabulary, and sim(w1, w2) is a cosine of similarity between two embedded vectors of words W1 and W2. We call the distributed lexical contrast vector model dLCE.
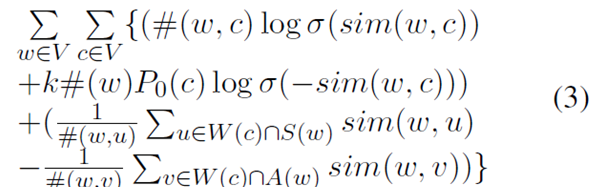
Compared with Equation 1, Equation 3 uses a slightly different approach to integrate lexical contrast information into the skip-gram model: For each target word w, we use only its antonym A(w) instead of its antonym. Synonym S(w'). Especially when we use a lot of training data, this integration method can train vocabulary vectors more efficiently during runtime.
The dLCE model is similar to the WE-TD model and mLCM model. However, the latter two models only match the vocabulary comparison information extracted from WordNet with each target word. The dLCE model compares the vocabulary contrast information with the target word for each single The context is matched to better capture semantic contrast information and classify the semantic contrast information obtained.
3 experiments
3.1 Experiment Settings
The corpus resource used for our proposed vector representation is currently one of the largest online corpora: ENCOW14A (Schafer & Bildhauer, 2012; Schafer, 2015), which includes 14.5 billion characters and 5.61 million different parts of speech. We use 5 characters to represent the original vector representation and the vocabulary vector model to display distributed information. We use vocabulary vector representations by training 500 dimensions of vocabulary vectors; set the number of k-negative samples to 15; set the threshold of secondary samples; ignore all vocabularies that appear less than 10 times in the corpus. The back-propagation value of the error is calculated by the stochastic gradient descent method to obtain the parameters of the model. The learning rate strategies involved are similar to the ones set by Mikolov et al. (2013), and Mikolov et al. set the initial learning rate to 0.025. We used WordNet and Wordnik to collect antonyms and synonyms. In total, we extracted 363,309 pairs of synonyms and 38,423 pairs of antonyms.
3.2 Differentiate Antonyms and Synonyms
The first experiment evaluated our vocabulary contrast vector by applying the vector representation of the improved weightSA score to tasks that distinguish between antonyms and synonyms. We use the English dataset (gold standard resource) described in the Roth and Schulte im Walde (2014) article, which contains 600 adjective pairs (300 antonym pairs and 300 synonym pairs) and 700 noun pairs (350 antonym word pairs and 350 synonym word pairs), 800 verb word pairs (400 antonym word pairs and 400 synonym word pairs). We used the average precision and an information retrieval metric used by Kotleman et al. (2010) to evaluate the calculation results.
Table 1 shows the results of the first experiment. This result compares our improved vector representation with the original LMI representation for cross-category comparisons, or uses singular value decomposition, or does not apply the method. In order to use the average precision to evaluate the word pairs step by step, we organized the synonym and antonym pairs according to the cosine of the score. If a synonym word pair belongs to the first half, the word pair will be regarded as positive; if an antonym pair belongs to the other half, the word pair will be regarded as positive. The optimization results shown in the table assign the average precision of the SYN to 1 and the average precision of the ANT to 0. The results in the table demonstrate that weightSA is superior to the original vector representation in a great deal of cross-reference.
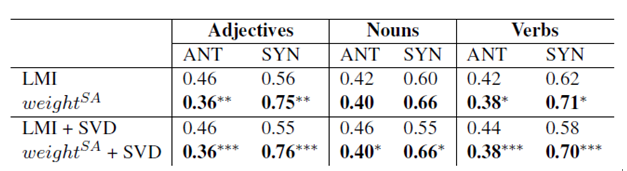
Table 1: Results of the average accuracy assessment of the DSM model
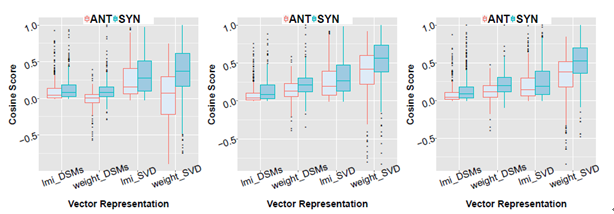
(a) Cosine of adjective word pair (b) Cosine of noun word pair (c) Cosine of verb word pair
Figure 2: Differences between the cosine of the antonym word pair and the synonym word pair
In addition, Figure 2 shows the median comparison of the cosines of the similarity between the antonym pair (red) and the synonym pair (green) in the cross-word comparison. The figure shows that the similarity cosine of the two semantic relations calculated using our improved vector representation shows a great difference compared to the original LMI notation, when using the SVD vector representation, this This difference is even more pronounced.
3.3 Influence of distributed vocabulary comparison method on vocabulary vectors
The second experiment evaluated the performance of our dLCE model using the task of distinguishing anonym-synonyms and lexical similarity. The similarity task requires the similarity between predicted word pairs. According to a golden artificial evaluation standard, the Spearman rank correlation coefficient Ï (Siegel & Castellan, 1988) is used to evaluate the ranking of the forecast results.
This paper uses the Silmlex-999 data set (Hill et al., 2015) to evaluate the performance of a vocabulary vector model for similarity predictions. The data set contains 999 word pairs (666 noun pairs, 222 verb pairs, and 111 adjective pairs). This data set was established to evaluate the various models in capturing word pair similarity, not word pairs. Relevance performance. Table 2 shows that our proposed dLCE model is superior to the SGNS and mLCM models, confirming that the lexical contrast information helps predict vocabulary similarities.
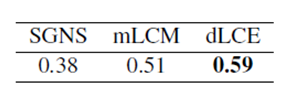
Table 2: Spearman rank correlation coefficient Ï in the Simlex-999 data set
Therefore, the improved differentiation between the synonyms in the dLCE model (word pairs with very similar meanings) and the antonyms (meaning highly relevant, but highly different word pairs) also supports the differences between similarities.

Table 3: AUC scores in identifying antonym tasks
We calculate the similarity cosine of the word pairs contained in the data set described in 3.2 to distinguish between antonyms and synonyms. Then we use the region under the ROC curve (AUC) to evaluate the performance comparison between the dLCE model and SGN and mLCM models. The results in Table 3 show that the dLCE model outperforms the SGN model and the mLCM model in this task.
4 Conclusion
This paper presents a new type of vector representation which can improve the accuracy of the similarity of vocabulary prediction between traditional distributed semantic models and vocabulary vectors. First, we use vocabulary contrast information to greatly enhance the weight features to distinguish between antonyms and synonyms. Secondly, we apply the lexical contrast information to the skip-gram model, which can successfully predict the similarity of the word pairs and also recognize the antonyms.
Manual Motor Starter,Motor Starter,KNS12,China Motor Starter
Wenzhou Korlen Electric Appliances Co., Ltd. , https://www.zjmotorstarter.com