
There is no doubt that the popularity of machine learning and artificial intelligence has increased dramatically over the past two years.
If you want to learn machine algorithms, where do you start? Take me as an example. I was studying in the AI ​​course during my study in Copenhagen. The textbook we use is an AI classic: Peter Norvig's ArTIficial Intelligence? —? A Modern Approach. I have continued to learn this lately, including listening to several technical lectures on deep learning in San Francisco and attending machine learning conferences. In June, I signed up for Udacity's Intro to Machine Learning online course, which has recently been completed. In this article, I want to share some of the most common machine learning algorithms I have learned.
I learned a lot from this course and decided to continue learning this professional content. Not long ago, I listened to several technical presentations on deep learning, neural networks, and data architecture in San Francisco, including a well-known expert in many fields at a machine learning conference. Most importantly, I registered Udacity's online course on machine learning in June, which has recently been completed. In this article, I want to share some of the most common machine learning algorithms I have learned.
Machine learning algorithms can be divided into three broad categories—supervised learning, unsupervised learning, and reinforcement learning.
Supervised learning is useful for training tagged data, but for other unlabeled data, an estimate is required.
Unsupervised learning, for the processing of unlabeled data sets (data without preprocessing), when it is necessary to explore its intrinsic relationship.
Reinforcement learning, somewhere in between, does not have precise labels or error messages, but there is some form of feedback for each predictable step or behavior.
Since I am on an introductory course, I have not studied intensive learning, but the following 10 supervised and unsupervised learning algorithms are enough to make you interested in machine learning.
Supervised learning
1. Decision Trees
A decision tree is a decision support tool that uses a tree-like graph or model to represent decisions and their possible consequences, including the effects of random events, resource consumption, and usage. Please take a look at the picture below, feel free to feel the decision tree length like this:
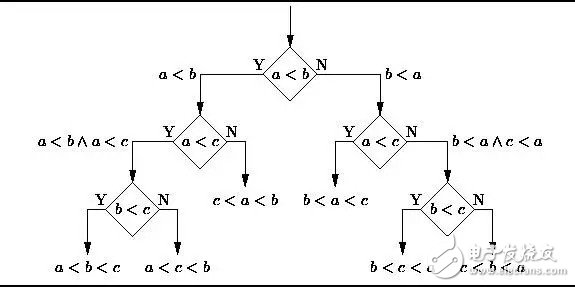
From a business perspective, decision trees use the least Yes/No problem to make the right decisions as much as possible. It allows us to solve problems in a structured, systematic way and get a logical conclusion.
2. Naive Bayes ClassificaTIon
The naive Bayes classifier is a class of simple probability classifiers based on the Bayesian theorem applied to the strong independence hypothesis of the relationship between features. The following figure is the Bayesian formula—P(A|B) represents the posterior probability, P(B|A) represents the likelihood, P(A) represents the class prior probability, (P (B) ) indicates the predictor prior probability.

Real life application examples:
Is an email spam?
An article should be divided into technology, politics, or sports
Does a paragraph express positive or negative emotions?
Face recognition
3. Ordinary Least Squares Regression
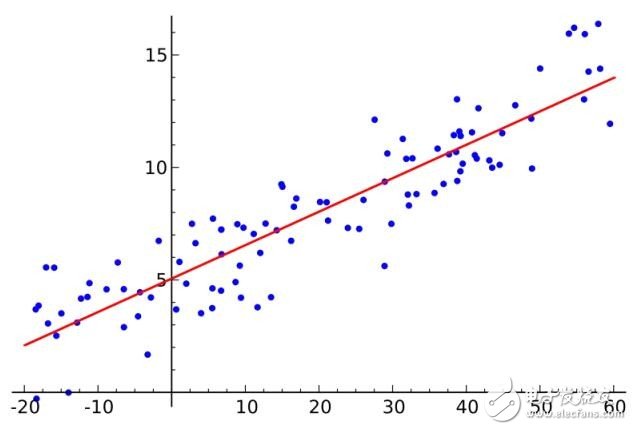
If you have studied statistics, you may have heard linear regression. At least the least squares is a method of performing linear regression. You can think of linear regression by letting a line pass through a set of points in the most appropriate pose. There are many ways to do this, and ordinary least squares is like this - you can draw a line, measure the distance of each point to this line, and add up. The best line should be the one with the smallest sum of all distances.
The linear method means that you are going to model a linear model, and the least squares method can minimize the error of the linear model.
4. Logistic regression (LogisTIc Regression)
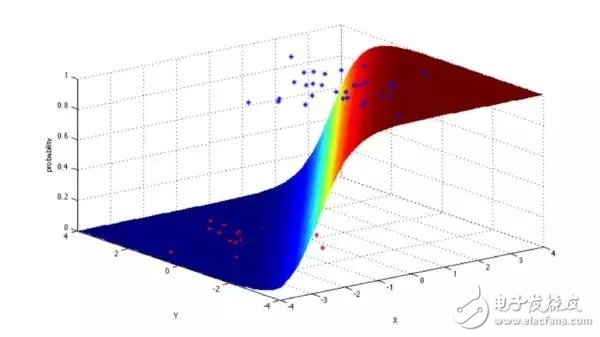
Logistic regression is a very powerful statistical method. It can be used to model data with one or more explanatory variables as a binomial type. By estimating the probability with a logical function of cumulative logic distribution, measuring the classification dependent variable and one or The relationship between multiple independent variables.
Usually, the use of regression in real life is as follows:
Credit evaluation
Measuring the success of marketing
Predict the profit of a product
Whether an earthquake will occur on a particular day
5. Support Vector Machines

SVM is a binary algorithm. Suppose that in the N-dimensional space, there are a set of points, including two types, and the SVM generates a hyperplane of the a(N-1) dimension, and divides these points into two groups. For example, if you have some dots on paper, these points are linearly separated. The SVM will find a line, divide the points into two categories, and keep them as far as possible.
In terms of scale, SVM (including appropriately adjusted) solves some of the most serious problems: advertising, human gene splice site recognition, image-based gender detection, large-scale image classification...
6. Integration methods (Ensemble Methods)
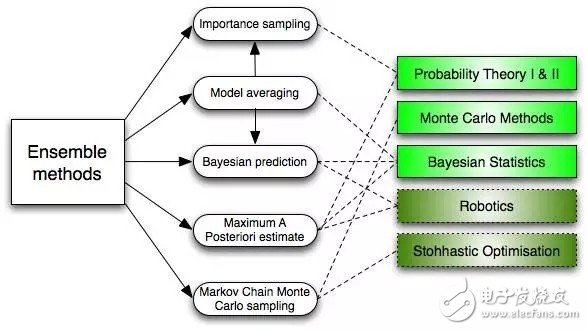
The integration method incorporates a number of algorithms, builds a set of classifiers, and then votes for their predictions with weights for classification. The original integration method was Bayesian averaging, but recent algorithm sets also include error-correcTIng output coding, bagging and boosting.
So how does the integration method work? Why are they better than separate models?
They balance the bias: just like if you balance a large number of pro-democracy votes and a large number of Republican votes, you will always get a less biased result.
They reduce the variance: the reference results of a large number of models are aggregated, and the noise is smaller than the single result of a single model. In finance, this is called diversification – a portfolio of stocks that mix and match a lot of stocks, with fewer changes than stocks alone.
They are unlikely to be over-fitting: if you have a separate model that is not fully fitted, you can model over-simple (over-fitting) with each simple method.
Unsupervised learning
7. Clustering Algorithms
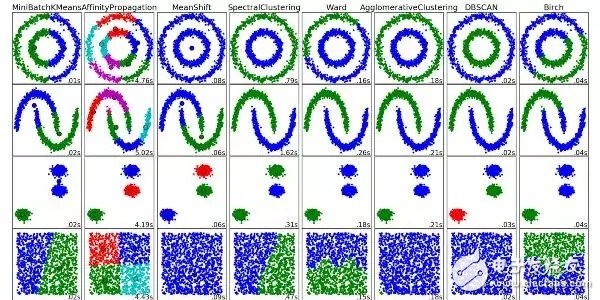
Clustering is the task of grouping a group of objects so that objects in the same group are more similar to each other than objects in other groups.
Each clustering algorithm is different, here are some of them:
Centroid-based algorithm
Connection-based algorithm
Dense-based algorithm
Probability theory
Dimensionality reduction
Neural network / deep learning
8. Principal Component Analysis
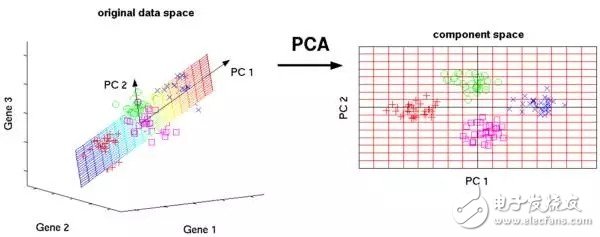
PCA is a statistical process that transforms a set of potentially related variables into a set of linearly uncorrelated variables by orthogonal transformations. These unrelated variables are principal components.
PCA applications include compression, simplifying data to make it easy to learn, and visual. It is important to note that domain knowledge is especially important when deciding whether to use PCA. It does not apply to data with a lot of noise (the variance of all components is high)
9. Singular Value Decomposition
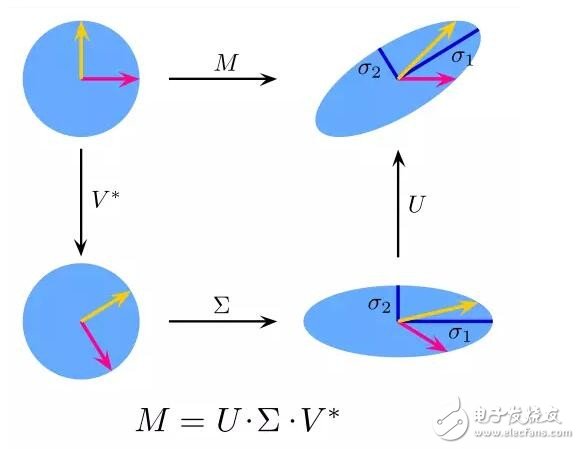
In linear algebra, SVD is a factorization of a particularly complex matrix. For example, a matrix M of m*n has a decomposition such as M = UΣV, where U and V are 酉 matrices and Σ is a diagonal matrix.
PCA is actually a simple SVD. In the field of computer graphics, the first face recognition algorithm uses PCA and SVD, uses a linear combination of eigenfaces to express facial images, then reduces dimensionality, and uses simple methods to match faces and people. Although today's methods are more complex, there are still many that rely on technologies like this.
10. Independent Component Analysis
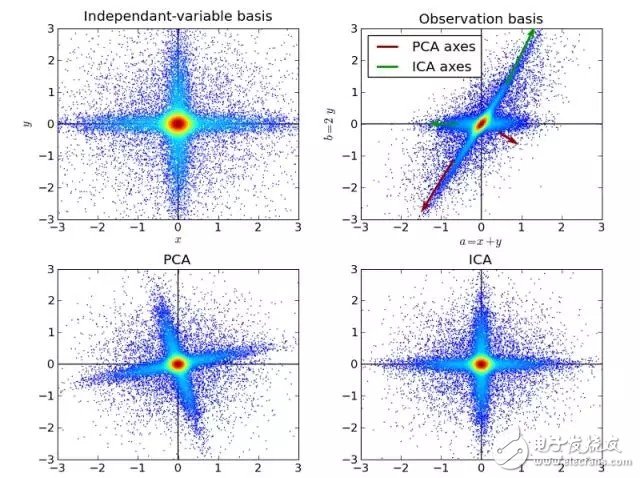
ICA is a statistical technique. It explores the hidden factors in the set of random variables, measurement data, or signals. ICA defines a generic model for observing multivariate data, usually a large sample database. In this model, it is assumed that the data variables are linear combinations of unknown and potential variables, and the combination is unknown. It is also assumed that the potential variables are non-Gaussian and independent of each other, which we call independent components of the observed data.
ICA has a connection with PCA, but a more useful technique can reveal potential factors in data sources when classic methods fail completely. Its applications include digital images, document databases, economic indicators and psychometrics.
Now you can start using your understanding of these algorithms to create machine learning applications that will give you a better experience.
Bt Megaphone,Megaphone Speaker,Bluetooth Megaphone,Megaphone Loudspeaker
Shangqiu Huayitong electronic technology co., Ltd. , https://www.huayitongmegaphones.com